
Background
Formatted SQL is does not run any better than unformatted SQL. The database really couldn’t care less whether you put your commas before or after each field name. For your sanity and to be an effective SQL writer I advise that you follow some formatting guidelines. In this post I will share how I format my SQL statements to increase my productivity. I define productive as being able to churn out accurate results from SQL and have code that is easy to follow, modify and debug. I am only going to focus on the SELECT statement which makes up 99% of SQL I write. Formatting your SQL code is a very personal choice and I am well aware that different people will swear by their formatting rules.
Sample problem
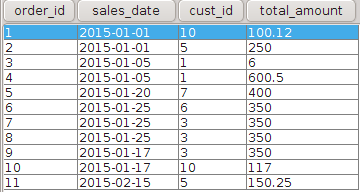
Here is a typical SQL usage scenario, business needs report with data in three tables, customer, sales and location. For January 2015, the reports needs to show the total number customers who reside in each postal code district and show total sales. This should be a simple statement SQL statement joining the three tables.
Possible issues with data
Whilst the SQL is easy, ensuring your results are accurate is the real challenge due to one of many possible reasons including:
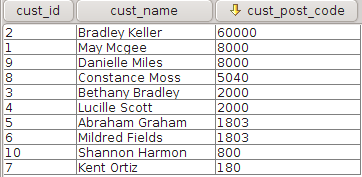
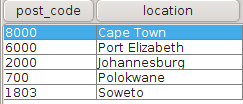
- Data may be from different sources. This means there is no guarantee that referential integrity exists across different tables. In simple English you cannot assume all post codes on the customer table are valid post codes and exist in the location table.
- The application on which the customer data is captured may not have data validation in place. Incorrect post codes may have been captured.
- The post code table may not have all post codes. New post codes may have been introduced that have not been added to the table since the last update.
First Principles
For me formatting SQL is as much about getting correct results from the SQL as it is about having clear SQL that is easy to follow. The first thing I do is write the statement below to get total number of customers. This is the number I am going to balance to after I have written out my full statement.
The first statement I write is:
SELECT
COUNT(DISTINCT cust_id) as count_customers
FROM
customers
Result:
| count_customers |
|---|
| “10” |
This query is important because it sticks to first principles. Since there are no SQL joins therefore no dependencies I know that this is the correct number of customers. I jot the result down because I need to always balance to this figure which is a convenient 10 for this post.
The next thing I do is add the necessary fields and tables to the query. I have highlighted the word add because with the formatting rules I follow I am able to comment out elements of the query to get the same results as when I was applying first principles. Below is the query I end up with formatted the way I format queries.
Formatted SQL
Below is my recommended formatted SQL followed by reasons for the formatting choices I have made.
SELECT
0
,c.cust_post_code
,p.location
,COUNT(DISTINCT c.cust_id) number_customers
,SUM(s.total_amount) as total_sales
FROM
customers c
JOIN post_codes p ON c.cust_post_code = p.post_code
JOIN sales s ON c.cust_id = s.cust_id
WHERE
1=1
AND s.sales_date BETWEEN '2015-01-01' AND '2015-01-31'
--AND s.order_id = 5
GROUP BY
c.cust_post_code
,p.location
Always use table alias
This future proofs your SQL. If you do not use a alias for each field taking part in the query and sometime in the future field with the same name is added to one of the tables used in the query. Your query and thus your report will generate an error (duplicate field name found).
Comma before field
When debugging/testing my query this allows me to comment and uncomment out fields easily without need to modify any other line in my query to ensure that I still have commas in the right place. I have seen posts where bloggers trivialise having to change another part of the query to ensure the comma is correct, but if you are in spend most of your time writing and testing SQL statements this is a big deal. You will be more productive this way. This works well in both the SELECT and GROUP BY sections of the query.
I use the SELECT 0 in development and tend to remove it before promoting code to production. It allows me to put comma before all fields. Without the 0, if I wanted to comment out c.cust_post_code which would be the first field, I would then have to comment out the comma at the start of the second field. I would have to do the same thing in the GROUP BY clause. The 0 eliminates this extra work.
JOIN on new line
Advantages of putting the JOIN statement on a new line include:- It is easy to see all the tables that are involved in query by just scrolling down list of JOIN statements.- Using the JOIN versus listing all tables and expressing relations in the WHERE clause keeps all relational logic in one place. It might not be possible to always have the JOIN statement in one line but at least in will be in one place.- Commenting out the JOIN is relatively easy. This is useful when debugging and you want to know which JOIN is causing the data discrepancy.
Column mode editing
When working with large numbers of fields column mode editing is very handy. Below is my first ever animated GIF showing how you can comment out all non aggregated fields. In practice I use column mode editing for more than just commenting out fields including:
- Creating indexes en mass
- When working with UNION statements with long lists of fields
- Commenting out long lists of fields in GROUP BY clause

Testing Query Results
I had to use OUTER join to list all customers because not all customers post codes had a corresponding post code in the location table. I was able to arrive at this finding by iteratively including and excluding different fields and tables in my query ensuring that I balance to the very first query that was based on first principles.
SELECT
0
,c.cust_post_code --
,p.location
,COUNT(DISTINCT c.cust_id) number_customers
,SUM(s.total_amount) as total_sales
FROM
customers c
--LEFT OUTER JOIN post_codes p ON c.cust_post_code = p.post_code
JOIN sales s ON c.cust_id = s.cust_id
WHERE
1=1
AND s.sales_date BETWEEN '2015-01-01' AND '2015-01-31'
--AND c.cust_post_code = 2000
--AND p.post_code = 200
GROUP BY
c.cust_post_code
--,p.location
Formatting SQL like this for me means that I don’t have to write separate tests to check my data. By commenting out a few lines I am able to test the accuracy of my data using first principles. This increases my productivity and accuracy of my reports.